When programming, always follow the camping rule: Always leave the code base healthier than when you found it.
— Martin Fowler, Refactoring
The Boy Scouts of America have a simple rule that we can apply to our profession. Leave the campground cleaner than you found it.
— Robert Martin, Clean Code
Many of us share the attitude expressed by the above Fowler and Martin quotes. The attitude presumes that code we’re working on now will change again soon, and we’ll reap the benefits of a refactor when that happens.
Here’s another common attitude: we don’t get enough time to refactor.1
These attitudes are related: insofar as we hope to make future work easier2, the above camping rule can lead to sub-optimal decisions about what code gets refactored. Those sub-optimal decisions can make us slower at building software than we could be, which means — among other things — that we have less time to refactor.3
How often do these sub-optimal decisions happen? The answer depends on how close the link is between current edits and future ones. I’ve already claimed that the link here is tenuous and suggested an alternative way of thinking about what code we should refactor, but here I measure the link between diffs (diff = number of lines changed) at time t and diffs at time t + 1. In other words, this post is about the extent to which diffs are serially correlated across months and quarters.
I’m only going to look at one repo here: the react.js repo. It’s the first one I chose and it happened to be one where diffs aren’t strongly serially correlated. The median of the 1-month autocorrelation for all source file diffs in the react.js repo is -.098. This means that if you’re editing a random file in the react repo and you refactor it hoping that someone will benefit from it in a month, you’re making a bad bet. If the react repo is representative of the codebases we tend to work in, we should rethink how we decide what code gets refactored.
In the first section, I breakdown the results I found while analyzing the react repo. In the next section, I go over the source code used for this analysis so you can make sure I’m not completely full of shit and so that you can run it on your own codebase and see how well the camping rule is serving you. I end with some caveats on the implications of this analysis and some suggestions for further questions we might ask.
Results
Before getting into the specific results, I want to clarify their format. I start with a list of files and their diffs grouped into buckets over 12 months. For example, here’s a subset of that list for the react repo:
packages/react-devtools-core/src/backend.js : 0 0 0 284 2 0 0 0 16 0 0 0
packages/react-devtools-core/src/editor.js : 0 0 0 190 0 0 0 0 0 0 4 0
packages/react-dom/src/client/ReactDOMHostConfig.js : 0 884 177 43 24 34 68 30 15 53 279 405
The first line of this list says that
- in the first three months,
backend.jshad 0 line edits - in the fourth month, there were 284 line edits
- in month 5 there were 2 line edits
- in the last month, there were 0 line edits
The 1-month-lagged autocorrelation for this file would be low because the number of lines changed in 1 month doesn’t tell you much about how many lines of code will be changed in the following month in that file.
The story is similar when I group diffs by quarter instead of month. The same files would like like this:
packages/react-devtools-core/src/backend.js : 0 286 16 0
packages/react-devtools-core/src/editor.js : 0 190 0 4
packages/react-dom/src/client/ReactDOMHostConfig.js : 1061 101 113 737
Note that I’m filtering out things like json files, jest snapshot files, and index.js files.
The results are presented as box and whisker plots of these auto-correlations over 1686 files in the react repo. This enables us to easily see the medians of the correlations across all files and the spread of the auto-correlations for all files, and it’ll help us avoid being mislead by outliers.
The histograms are plotted with the hist R function with it’s default parameters.
Monthly serial correlations
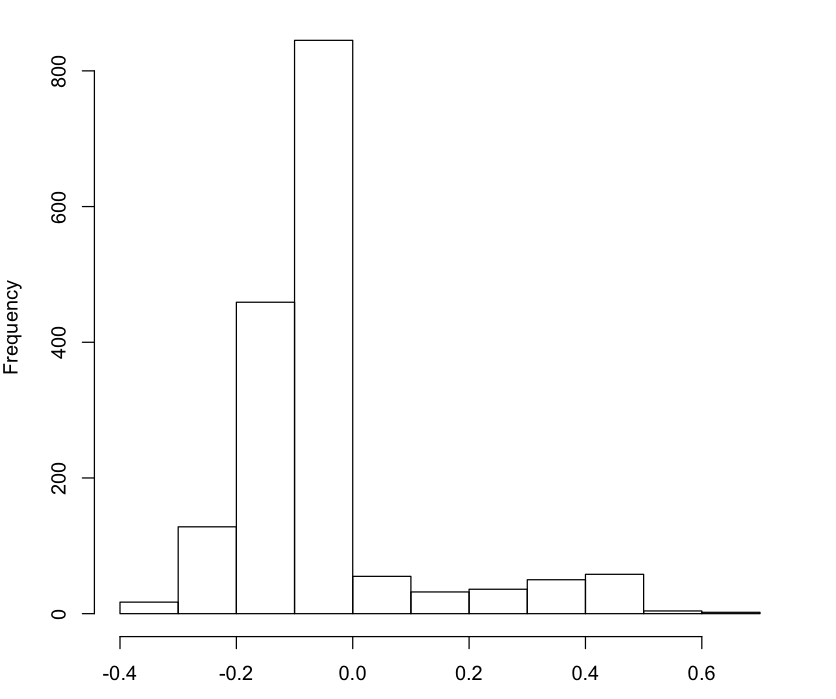
Two things I want to highlight here.
First, the median of the auto correlations across all files is only -.0984. This means that 50 percent of the autocorrelations for files are at this value or less. Again, this shows that refactoring a random file in hopes that someone will come along next month to benefit from your work is not a good bet.
Those of us who lack strong intuitions about what good correlation coefficients look like (I’m one of them, to be honest) can get a rough idea of what this number conveys by just looking at the time series data for a bunch of random files:
fixtures/fiber-debugger/src/describeFibers.js : 0 111 0 0 0 0 0 0 0 0 0 0
src/devtools/views/Profiler/CommitFilterModalContext.js : 0 35 0 0 0 0 0 0 0 0 0 0
src/devtools/views/Components/Element.js : 118 233 0 0 0 0 0 0 0 0 0 0
scripts/eslint-rules/__tests__/no-production-logging-test.internal.js : 0 0 0 0 0 0 234 111 0 0 0 0
packages/shared/ReactTypes.js : 0 114 90 20 7 10 5 12 19 3 64 7
Note that while there are some files that see a lot of changes consistently, most files just get changed and aren’t touched for quite a few months. Of course, this means the serial correlation for that file isn’t very strong.
Here’s the second thing I want to highlight: there’s a lot of outliers here (558). So, there’s a lot of variability in the autocorrelation of diffs across files. This variability challenges the idea that we’re making optimal bets by always refactoring files we touch.
Quarterly serial correlations
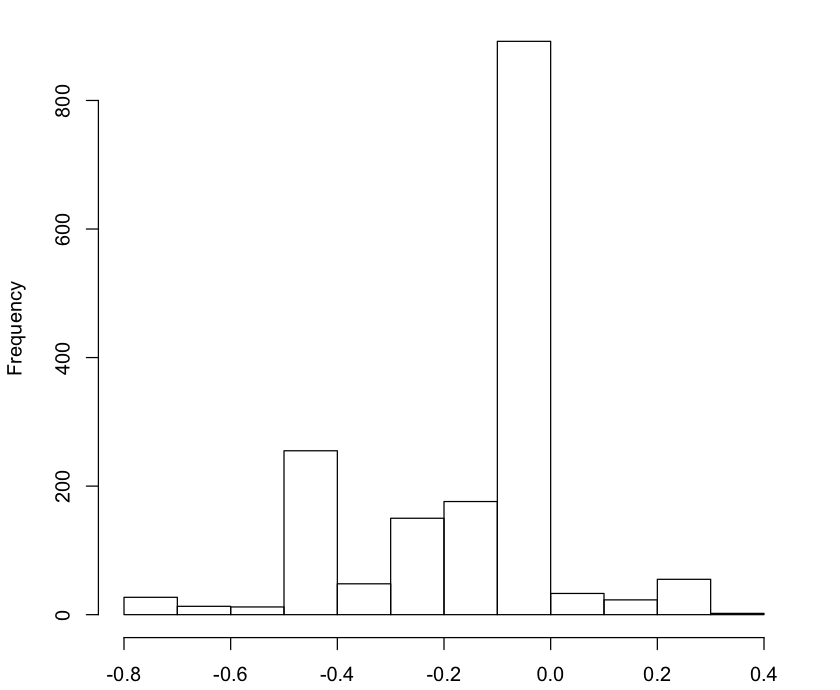
Here’s the quarterly serial correlations. 117 outliers this time. 75% of the files have a correlation value of -.083 or less.
The motivation for considering both monthly and quarterly serial correlations was to address the objection that monthly time slices for diffs were too thin to appreciate the relationship between diffs at different times. As you can see, the correlation gets a little better, but not by much.
If quarterly is still too thin a time-slice, this still implies we need to rethink our refactoring choices. If it usually takes over 3 months to reap the benefits from a refactor, then we have to weigh our decision to refactor against more immediate gains we may realize by doing something else, like refactoring a file that will change more frequently or release a feature more quickly.
Methods and Source
Bash + Git
First, I wrote a bash script that asked git for the diffs for every file in the repo over the last year and broke those diffs into monthly buckets. git diff --numstat and git log --format=format:%H --before $before --after $after were especially useful here. Here’s are the highlights of the bash script4:
#!/bin/bash
months=('May-2019:June-2019' 'June-2019:July-2019' 'July-2019:Aug-2019' 'Aug-2019:Sept-2019' 'Sept-2019:Oct-2019' 'Oct-2019:Nov-2019' 'Nov-2019:Dec-2019' 'Dec-2019:Jan-2020' 'Jan-2020:Feb-2020' 'Feb-2020:March-2020' 'March-2020:April-2020' 'April-2020:May-2020')
#...
echo "Month Lines-Added Lines-Deleted Path"
for month_pair in "${months[@]}"; do
after=$(split_month_pair 1 "$month_pair")
before=$(split_month_pair 2 "$month_pair")
first=$(first_commit_of_month "$after" "$before")
last=$(last_commit_of_month "$after" "$before")
if [ -z $first ]; then
continue
fi
git --no-pager diff --diff-filter=ACDM --numstat $first $last |
grep ".js$" |
# filtering out weird files like snapshots
xargs -I {} echo "$after:$before {}"
done
If you run this on the react repo, for example, you wind up with output that looks like this:
Month Lines-Added Lines-Deleted Path
May-2019:June-2019 7 6 shells/dev/src/devtools.js
May-2019:June-2019 12 6 shells/utils.js
May-2019:June-2019 116 0 src/__tests__/__snapshots__/inspectedElementContext-test.js.snap
...
June-2019:July-2019 7 0 packages/create-subscription/npm/index.js
June-2019:July-2019 23 0 packages/create-subscription/package.json
June-2019:July-2019 489 0 packages/create-subscription/src/__tests__/createSubscription-test.internal.js
...
Dec-2019:Jan-2020 2 2 packages/react-interactions/events/src/dom/ContextMenu.js
Dec-2019:Jan-2020 2 2 packages/react-interactions/events/src/dom/Drag.js
Dec-2019:Jan-2020 152 69 packages/react-interactions/events/src/dom/Focus.js
...
April-2020:May-2020 1 0 scripts/rollup/validate/eslintrc.rn.js
April-2020:May-2020 1 0 scripts/rollup/validate/eslintrc.umd.js
April-2020:May-2020 19 19 scripts/shared/inlinedHostConfigs.js
R + Jupyter5
From here, it’s easy to import this into R as a data frame and to combine the lines added a lines deleted into a Total Diff column:
changes <- read.table('./react.txt', header=TRUE)
changes$Total.Diff <- changes$Lines.Added + changes$Lines.Deleted
Next, we build a map from files to a monthly time-series of diffs. Here’s the output:
packages/react-devtools-core/src/backend.js : 0 0 0 284 2 0 0 0 16 0 0 0
packages/react-devtools-core/src/editor.js : 0 0 0 190 0 0 0 0 0 0 4 0
packages/react-dom/src/client/ReactDOMHostConfig.js : 0 884 177 43 24 34 68 30 15 53 279 405
packages/react-dom/src/client/ReactDOMInput.js : 0 426 0 0 0 0 0 13 8 0 16 0
packages/react-dom/src/events/SyntheticWheelEvent.js : 0 43 0 0 0 0 0 0 18 0 0 0
Then, we loop over all the keys in our map and build a matrix of autocorrelation calculations, where the rows are files and the columns are autocorrelations at various lags (up to 6):
auto_correlations <- list()
for (k in keys(files_to_time_series)) {
diff_time_series <- unlist(files_to_time_series[[k]])
auto_corr <- acf(diff_time_series, lag.max = 1, plot = FALSE)$acf
auto_correlations <- list.append(auto_correlations, auto_corr)
}
acf_matrix <- t(array(unlist(auto_correlations), dim=c(2, length(auto_correlations))))
From here, we can calculate all the stats we covered in the results section with simple calls to apply.
Caveats, Objections, and Future Directions
This analysis is far from perfect. In this section, I address some limitations and objections to it. Along the way, I point to the future directions suggested by these caveats and objections.
Caveats
Refactoring helps us now too
Refactoring’s benefits aren’t limited to making future changes easier. Sometimes, refactoring makes the current task easier. As Kent Beck says,
for each desired change, make the change easy (warning: this may be hard), then make the easy change
— Kent Beck 🌻 (@KentBeck) September 25, 2012
When refactoring is justified solely because it makes current work easier, we should refactor. For example, sometimes refactoring helps us understand the code we’re changing. The above analysis doesn’t challenge the value of this kind of refactoring. In cases where we appeal to the future benefits of refactoring, the above data suggests6 we should be more cautious.
Libraries vs. Apps and does this result generalize?
I’ve only looked at one repo here, and it’s a library project. Libraries may have different editing patterns than applications. I would expect edits to be more serially correlated in libraries as compared to applications, but that could be completely wrong. I’d rather make the source code I wrote for this analysis more readable and reusable so that people can just run the analysis on their repo instead of trying to make a more convincing general claim about editing patterns of different types of projects. If it turns out there are project types with strongly serially correlated edits, great! The campground rule will serve those projects very well.
Counting diff sizes vs. counting whether a file is edited at all
I’ve opted to count diff sizes here, which could make the autocorrelation look worse than if I simply counted whether a file was edited. In the case of the react repo, the median monthly serial correlation is if we ignore diff sizes is the same, but there is a lot less variability in the data with this way of counting (267 outliers vs 558). In this particular case, there isn’t much of a difference between the counting methods, and in general, it’s not clear that one method of counting is strictly better. If we only count whether a file is edited, we’re losing some information about how big the diff is and that does seem to matter in determining whether a file will be edited in the future.
Objections
What about the benefit of refactoring on future reading of files?
One obvious objection here is that a refactored file may be beneficial even if no one is editing that file in the future. Even if a file is merely read in the future, the refactoring could be useful. Two things here. First, insofar as viewing files are correlated with editing them, this objection lacks force. Second, insofar as viewing files doesn’t correlate with editing them, we have another interesting direction to pursue in figuring out how to make better refactoring decisions. Let’s not speculate here about the relationship between reading and editing files. We’ve built god knows how many event tracking tools for other purposes. Let’s build a system that tracks how often source files are read. If someone built this and showed that file views were serially correlated, I’d welcome that as a step forward.
Won’t we eventually wind up in an okay codebase if we consistently follow the campground rule?
Another obvious objection is to restate the motivation for the campground rule, which is the idea that in theory, if we always slightly improve code we happen to touch, we’ll slowly work towards a state where the most touched files are the easiest to change. That may happen, but we’d be better off if we knew what refactorings were most useful ahead of time instead of hoping we’ll eventually wind up with the most touched files being pristine. More mature industries don’t rely on this sort of wishful thinking. Instead, they have sophisticated techniques for determining where to invest their time.
For example, Disney doesn’t tell their technicians to do preventative maintenance for every ride, churro deep fryer, and AV system they happen to be touching. Instead, they make statistically informed guesses at when those machines will fail and balance the cost of doing preventative maintenance now against everything else they might do to streamline their operations. We should have tools and practices like this as software engineers. I’ve already made some suggestions in this direction, but I more interested in seeing more discussion about how we move in this direction than I am in pushing my particular solution.
Notes
-
Fowler says this in Refactoring. ↩︎
-
See this caveat for why this phrase is italicized. ↩︎
-
Easy example: Management isn’t rushing your work. You happen to have plenty of time to finish the ticket you’re currently working on, so you clean things up a bit while you work and commit your code, feeling like a real boy scout coder. Then, for whatever reason, you fall behind while working on the next feature. You realize that you’re working in a part of the codebase that a) changes very frequently and b) implements the most important feature for the business. Unfortunately, you don’t have the time to refactor this code while you work. You bemoan the lack of time that management gives you for refactoring. ↩︎
-
You can see the entire notebook [here](./Are Code Diffs Serially Correlated.ipynb). ↩︎
-
I refuse to treat data as a plural noun. It’s weird, and people have been saying that it’s fine for it be singular for decades. See Elements of Style, for example. ↩︎